
This Open Source PDF Parser Ranks First Globally
Open source PDF parser ranks first in accuracy. 0.93 table extraction with JSON Markdown output. Fast local or high accuracy hybrid mode. Free OCR for 80+ languages.


There’s a dedicated benchmark project on GitHub that compares mainstream PDF parsers:
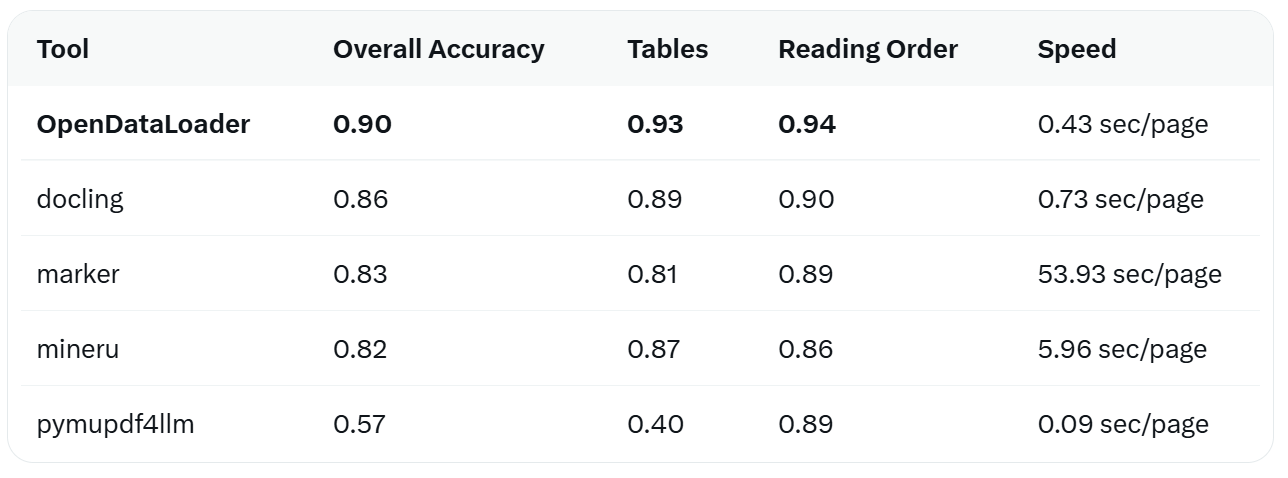
OpenDataLoader ranks first. Especially in table extraction, it achieves 0.93 accuracy, 4 percentage points higher than the second place.
One thing to note: marker is the slowest (53 sec/page), while pymupdf4llm is the fastest (0.09 sec/page). OpenDataLoader at 0.43 sec/page falls into the “not the fastest, but very accurate” category.
